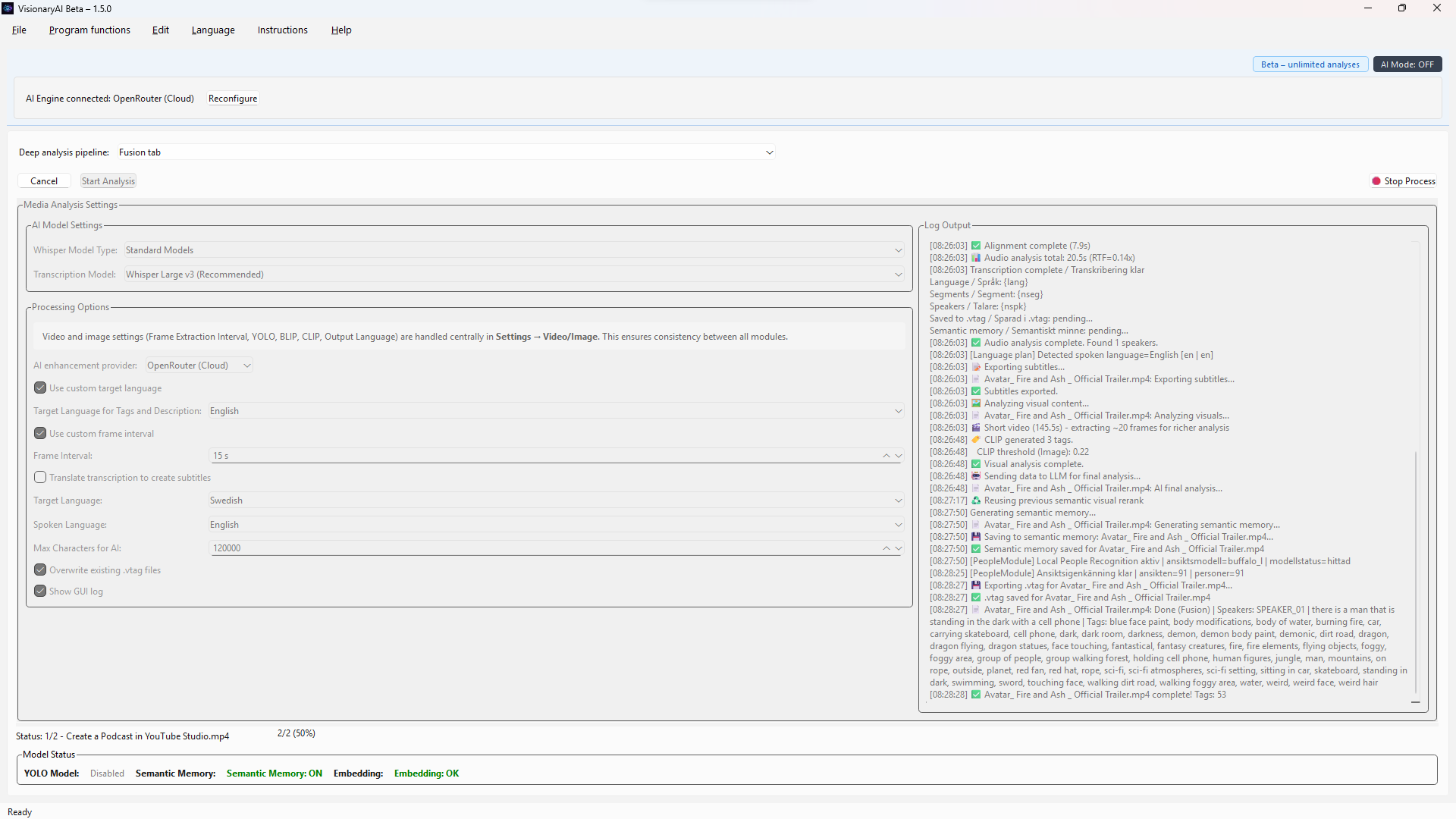
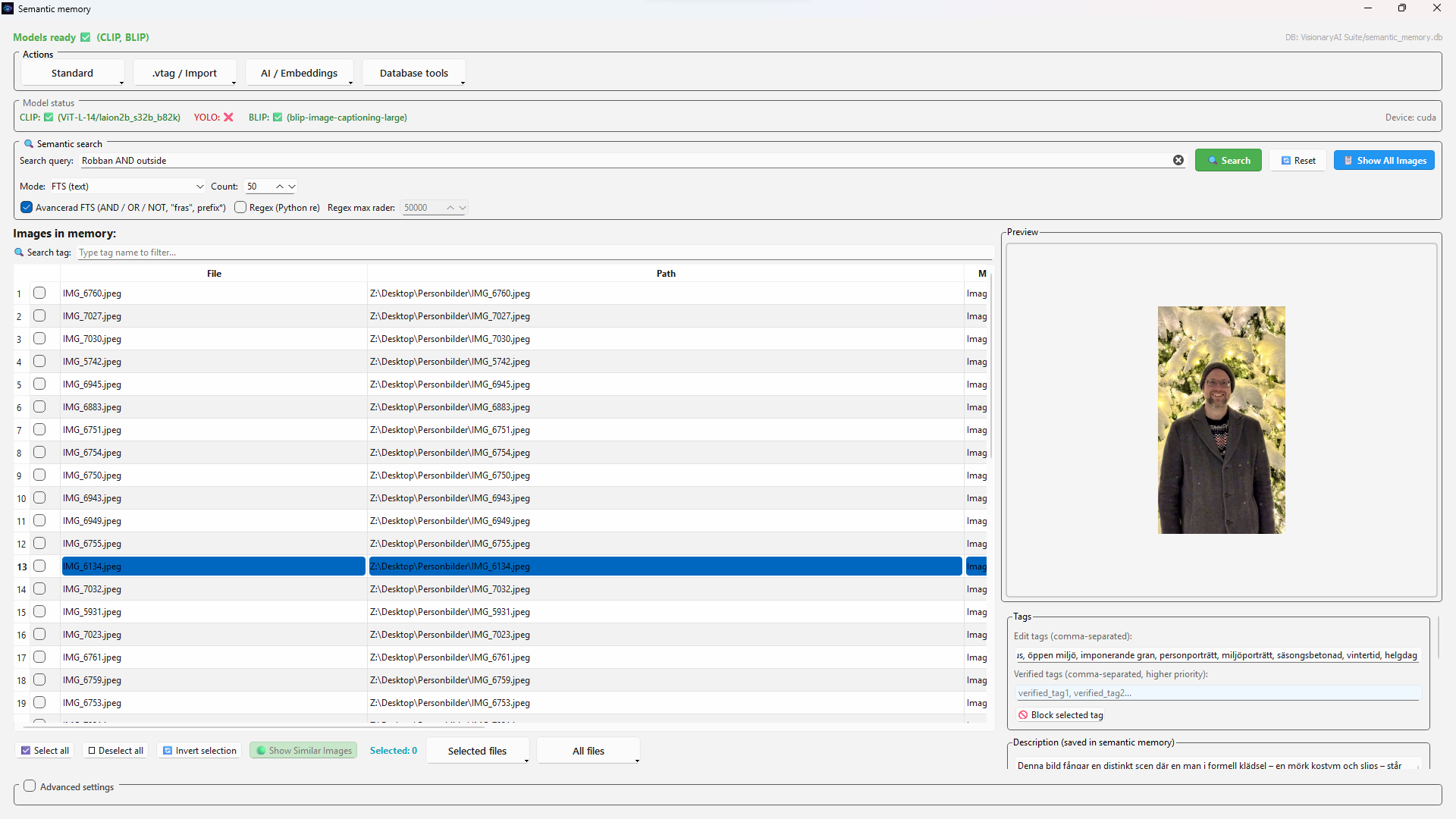
Real Multimodal Video Understanding is now operational
Vision models analyze real video frames, align them to timeline events, and fuse vision with speech, OCR and metadata — on your hardware.
Vision LLM
Timeline
OCR fusion
Local-first
What changed
Real video frames are sent to vision models. Timeline events are grounded in pixels, not re-summaries of captions.
Why it matters
Scene understanding, speech and on-screen text connect over time — searchable, evidence-backed, and persistent in .vtag metadata.
What is now possible
Find clips by what was seen, said or read on screen. Build multimodal archives that reason across time.