
Frame extraction
Scene-aware sampling aligned to cuts, motion and dialogue boundaries.
Home Platform Vision Intelligence
Real multimodal video understanding — frame extraction, Vision LLM analysis, timeline grounding and evidence-based fusion. The full technical story behind the homepage breakthrough.
Early AI tagging treated media as filenames and labels. VisionaryAI Suite now operates as an early breakthrough in grounded multimodal analysis — extracting real frames, building multimodal payloads with actual image data, and writing searchable timeline events that persist in .vtag metadata and Semantic Memory.
Video is no longer a black box of transcription and tags. It becomes a time-indexed intelligence surface where vision, speech and metadata are fused with evidence — not guesswork.
The pipeline extracts representative frames from video and sends them to Vision-capable models (including Gemma Vision via LM Studio). Analysis is grounded in pixels — not re-summaries of existing captions.
Scene-aware sampling aligned to cuts, motion and dialogue boundaries.
OpenAI-compatible vision messages with real image bytes. See architecture.
Each conclusion maps to timecodes and evidence sources on the multimodal timeline.
Scene narratives cover composition, action, atmosphere and on-screen detail — explicitly tied to frame evidence. Descriptions are useful for search, review and catalog export, while diagnostics show which frames supported each claim.
Example output style
“At 00:02:18 the frame shows a presenter at a desk with a slide titled ‘Benchmark Dashboard’; studio lighting, shallow depth of field.”
Linked to frame thumbnails, confidence and grounding scores — inspectable in Vision diagnostics. Diagnostics detail →
Vision LLM output is one layer in a fused stack: Whisper transcription, OCR, BLIP/CLIP signals, file metadata and Semantic Memory indexing combine into coherent timeline intelligence.
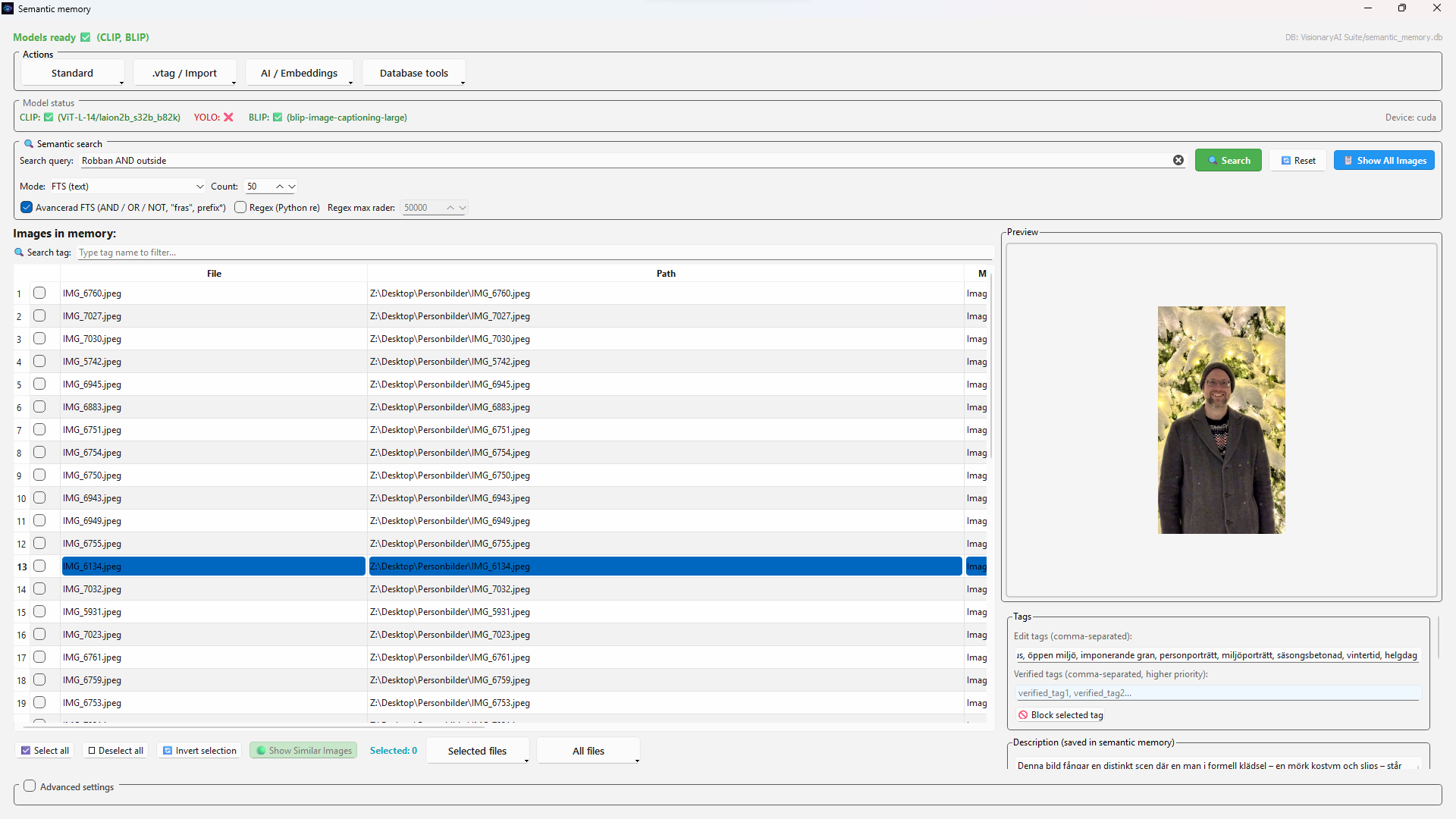
Architecture, payload structure and OCR fusion paths are documented on the architecture page. Grounding and hallucination control are on grounding & evidence.
The multimodal timeline surfaces frame-grounded scene events, confidence scores and evidence sources. Additional UI shots live in the gallery.
Operational in current beta builds. Request access for guided setup with LM Studio and Gemma Vision.