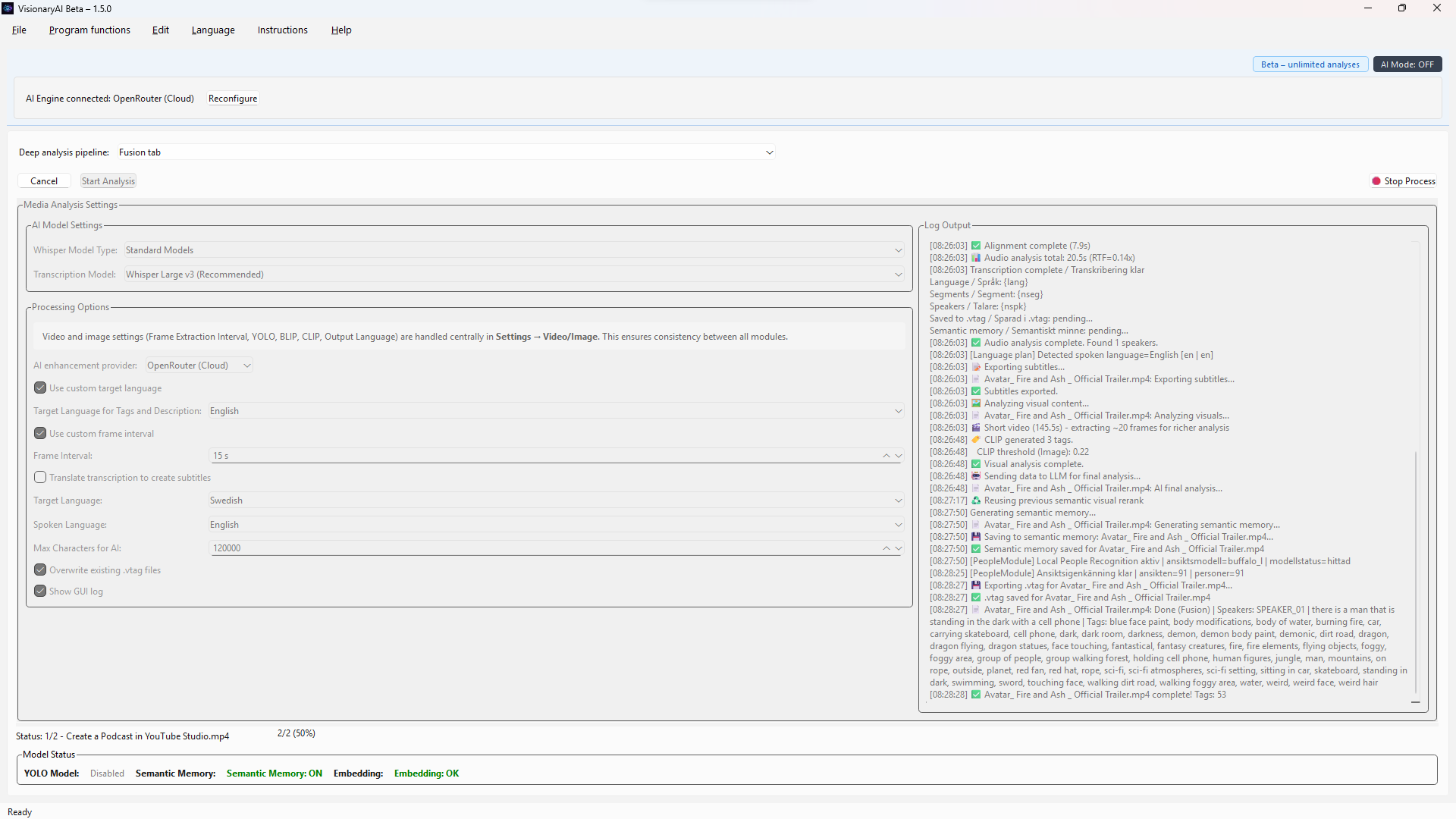
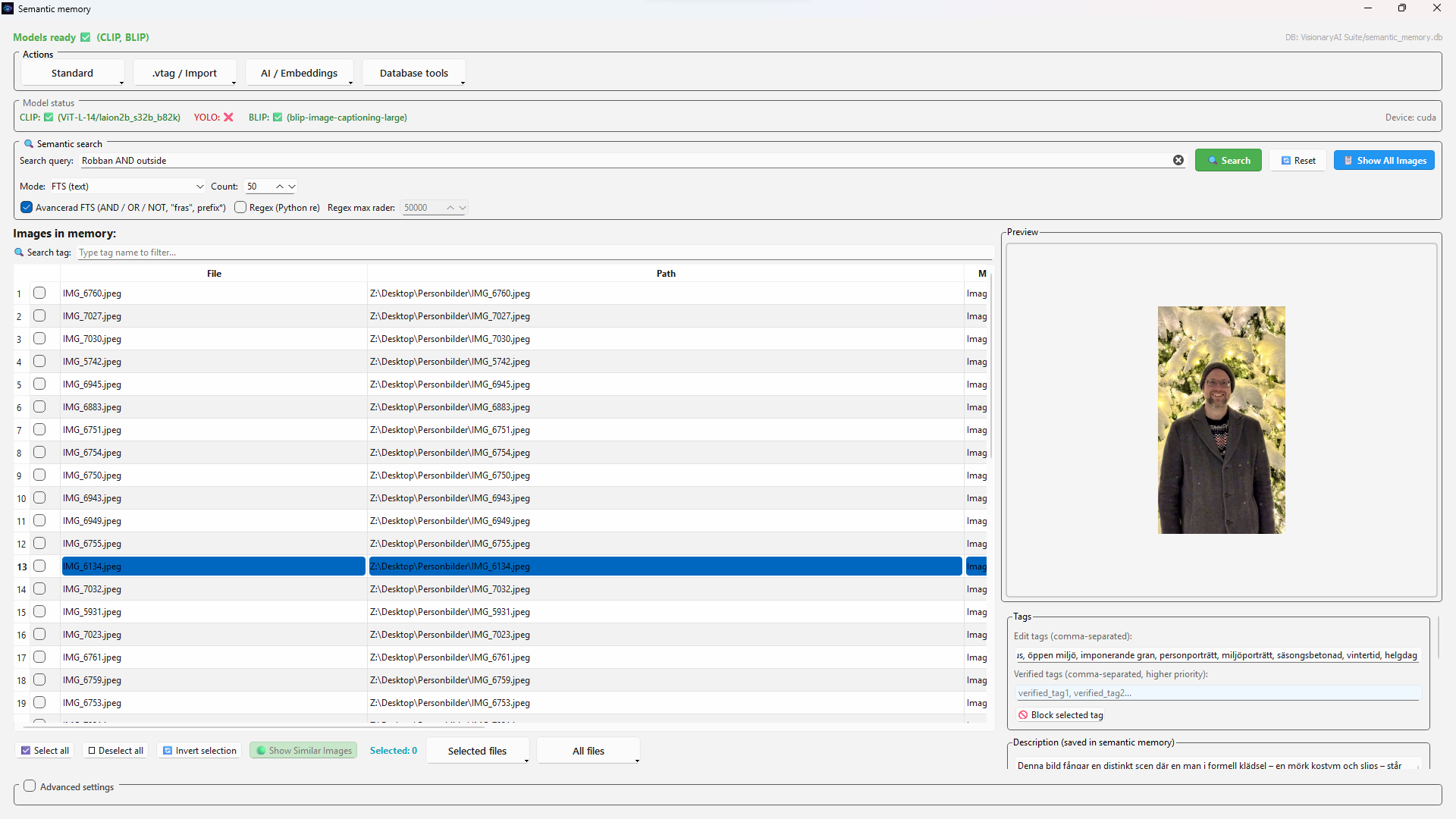
Verklig multimodal videoförståelse är nu operativ
Visionmodeller analyserar riktiga videobilder, kopplar dem till tidslinjehändelser och fuserar vision med tal, OCR och metadata — på din hårdvara.
Vision LLM
Tidslinje
OCR-fusion
Local-first
Vad som ändrats
Riktiga videobilder skickas till visionmodeller. Tidslinjehändelser grundas i pixlar — inte omskrivna bildtexter.
Varför det spelar roll
Scenförståelse, tal och text på skärmen kopplas över tid — sökbart, evidensbaserat och beständigt i .vtag-metadata.
Vad som nu är möjligt
Hitta klipp utifrån vad som synts, sagts eller lästs på skärmen. Bygg multimodala arkiv som resonerar över tid.